This Blog Contains the summary of the Google Summer of Code 2016 project with WSO2
IMPORTANT: The Links needed for final evaluation and final documentation are given at last.
| Overview
| Batch-Processing Vs Streaming Learning
| Apache Spark & Mini-Batch Learning
| Apache SAMOA & Streaming Learning
| WSO2 ML (Machine Learner)
| WSO2 CEP (Complex Event Processor)
| Solution
| Architecture
| Implementation
| Getting Started
| WSO2 Siddhi Query for Streaming ML analysis
| GSOC Final Evaluation Links
Overview
This project is to implement incremental machine learning algorithms to re-train machine learning models real time extending WSO2 Machine Learner (ML) for predictive big data analysis with the streaming support and WSO2 CEP (Complex Event Processor) extension support which can be deployed distributedly for massive online analysis. This solution provide hybrid and easily adoptable solution for both volume centric and velocity focused big-data analysis realizing the nature and the form of the big data. Therefore anlaysing data real-time with reduced latencies with incremental machine learning algorithms such as GSD (Stochastic Gradient Descent) Optimization and mini-batch processing with the concepts such as data horizon and data obsolences is the primary focus of the initial project. you can find the WSO2 project idea here and my project proposal here.
Batch-Processing Vs Streaming Learning
It is paramount imporatant to underestand the nature of the analysis to come up with a soultion for data analysis.Batch-Processing and supported algorithms for retrain ML models are to address the increasing vloume of the data. But with the rapid growth of the Internet of things (IoT) the velocity of the data is becoming vital to reduce the responce time such as in the case of sensor data processing. Mini-Batch processing is the easier way to handle large scale data which can be processed distributedly and independently. Batch Processing is the efficient way to address high volume of data where algorithms such as MapReduce are used to divide massive datasets across multiple distributed clusters for processing. But studies has shown that to extract near real tim insight of massive data, it is much better to use streaming learning. But with the nature if data it is paramount important to handle two scenarios in a hybrid soultion to handle both adoptably.
Apache Spark and Mini-Batch Processing
Spark has mini-batch processing based incremetal algorithms which is currenlty one of best solution for distributed processing with the fastest MapReduce algorithm than Hadoop. And also Spark has streaming solution which divide massive data sets or data streams into distributed streams and process against incremental algorithms. Apache Spark has a incremental learning algorithm support sudh as mini-batch algorithms, (SGD) stochastic gradient optimizations. Storm is the underlying distributed stream processing framework for spark. Thei streaming solution is advances to their MLLib, which mae use of same set of algorithms upon distributed streams fro streaming analysis. Therefore Spache Spark is ideal for handling high volume of data rather than processing faster which may be the case in extracting near insight of streaming learning. Most important factor is that even though the Apache Spark support mini-nbatch learning we can extensd its features to train models and retrain them as streams in real time as micro batches by reducing the batch size. This is not encouraged when the massive data volume is the critical factor for the anlaysis. Because in the batch-processing there is always a additional delay. Batch processing is really good for the situation where we need strategic insight when there is no need to process data in real time. Therefore spark is ideal for mini-batch processing scenarios.
Apache SAMOA and Streaming Learning
SAMOA (Scalable and Massive Online Analysis) is one of the emerging technologies that can be used for streaming analysis in real time. This SAMOA has already solved the scalability issues arised with its predecesors MOA, WEKA etc. This SAMOA is processing streams real time and can do fast retraining in real time analysis. And also SAMOA can be deplyed distributedly and process in a distributed cluster which can be powered by Storm, Samza and S4.With the scalable and flexible architecture SAMOA can support streaming learning with massive data. And also it can support both types of streaming learning.
- Native Stream Processing (tuple-at-a-time processing).
- Micro Batch Processing.
Both approaches have it's pros and cons. If we need to do massive analysis and resond real time, the native learning approach is more appropriate. Though this apprach is resulting in lowest possible latency, as long as the data volume is getting bigger it is not computationally efficient.In that case processing can be done as micro-batch processing with relevant ML algorithms. More importantly SAMOA provides basic building blocks wchich can be used for comples streaming analysis topologies which make it more scalable. You can find more information on Apache SAMOA here.
WSO2 ML (Machine Learner)
WSO2 use carbon-ml as their machine learning (ML) backbone which is based on the famous Apache Spark. With objective of supporting Big Data with a massive online analysis their intial project idea to extend their ML capabilities to real time retrain ML models with time without forgetting past which is the current scenario. Therefore the objective is to retrain with present data and past insight of data (basically the past ML models) and retain them fro predictions with prediction streams. In this way they do not need to store massive amount of datasets to training where model contains the insight of data. Currently WSO2 ML has different extensions to work with their CEP (Complex Event Processor) which is their stream/event-processing solution. For more information and documentation of WSO2 ML please check here. Ultimate objective of this project is to develop API with a CEP siddhi extension that can be deployed on carbon-ml and as well as standalone siddhi extension.
WSO2 CEP (Complex Event Processor)
CEP is their main event/stream processing framework which is built upon Apache Storm for distribution. CEP can handle streams and events in better way so we can perform integration, division etc. Therefore CEP has the potential to act as a stream processing engine which is similar to Apache spark streaming. CEP can deploy CEP siddhi extensions which are very easy to build and integrate with the CEP and siddhi queries. Complete set if instructions and guidance i used to develop CEP siddhi extension for my analysis is build with the help of WSO2 documentations of ML CEP extension. And also integration of the extensions with the CEP was done with this blog. For more information on WSO2 CEP can be found here. In my solution i have created three CEP siddhi extensions for my project.
Solution
We have provided the two solutions based on the WSO2 ML team requirement. This two solutions address two different aspects of big real time data analysis. high data volume aware solution which can address streaming learning and purely streaming aware solution which can address the volume by using micro-batch processing. They are spark based and samoa based real time predictive big data analysis. According to the WSO2 project idea the first implementation is based on the Apache Spark mini-batch processing and incremental learning algorithms such as SDG (Stochastic Gradient Descent) Optimization for Streaming Linear Regression, mini-batch clustering for streaming Kmeans Clustering. Both algorithms periodically retrain and update the ML model and both have their own CEP siddhi extension to invoke from CEP side for predictive analysis. But additionally after mid-review of GSOC WSO2 ML is looking for much better streaming solution. Therefore i have do review on SAMOA framework and integrate it with the cep for high end streaming learning. Therefore As the second phase of my project i have to integrate novel and advanced samoa architecture for real time streaming predictive analysis with a CEP siddhi extension support to deply in the CEP side.Therefore in the complete project i have developed three core modules,
- Apache Spark based Streaming Linear Regression with mini-batch SGD (Stochastic Gradient Descent) Optimization
- Apache Spark Based Streaming Kmeans Clustering with mini-batch clustering
- Apache Samoa Based Streaming Clustering (Integration of SAMOA with WSO2 CEP)
Architecture
- Spark Based Real Time Predictive Big Data Analysis
Both Streaming Linear Regression with SGD and Streaming Clustering withi mini-batch clustering is based on the same architetcure with different Siddhi extensions and core classes. In both spark cases Streaming classes inside my API handles the mini-batch processing.
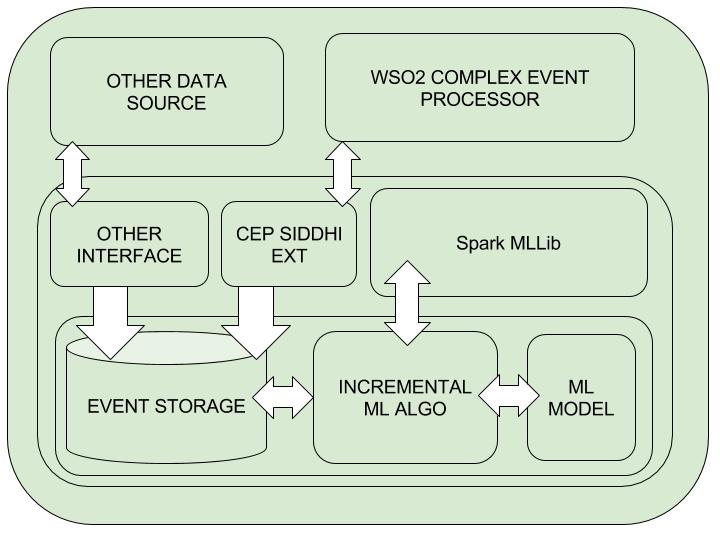
Though the classes are named as Streaming.. they can use for both cases mini-batch learning and streaming learning. Spark based architecture is purely mini-batch learning and samoa based implementation is native streaming learning one. But as long as they have opposite counterparts we can use two implementations wiseversa. We can use saprk based implementation for streaming by reducing batch sizes to micro batches and we can use samoa based architecture to micro-batch learning. In the spark case the learning cycles are based on the minibatches and not as streams which may be good for high volume of data.
- Samoa Based Real Time Massive Predictive Analysis
Integration of SAMOA (Scalable and Massive Online Analysis) with WSO2 CEP is a challenging task. To do that i had to go through both CEP architecture and SAMOA architecture. In Samoa by using their basic building blocks we can create new predictive analysis ML topologies to train ML models learn from data by extracting insight of near massive data. To integrate SAMOA with the new framework such as WSO2 CEP, we should have a good knowledge to handle samoa blocks. By this way we can feed data coming from the CEP to SAMOA ML topologies built for our purposes. To make use of the SAMOA for custom integration please look at samoa here. For CEP and our API integration SAMOA, customized SAMOA modules are used which we will discussed in the Implementation. In the SAMOA integration its is paramount important to decide the architecture for core to handle data as streams for real time learning. You can find a custom SMOA Task which can be build with basic SAMOA component in the following.
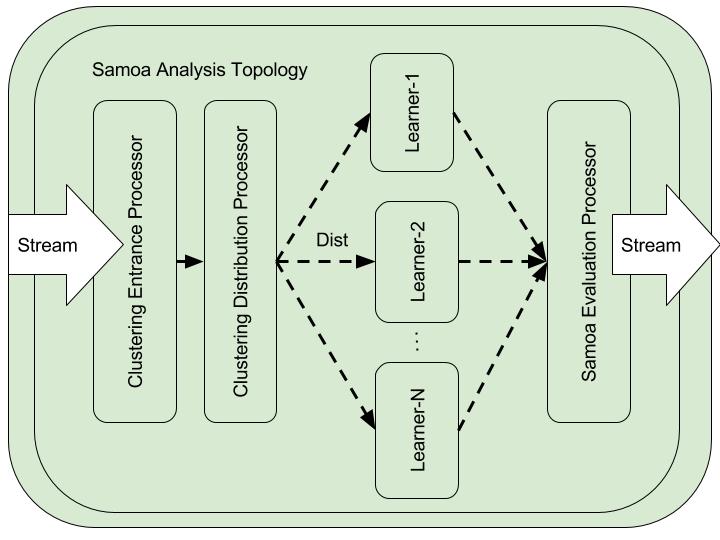
Overall Architecture of the SAMOA based implementation is looks like below when SAMOA is integrated with CEP extension to feed data streams. Because of th simple and distributed nature of the SAMOA, it is very easy to build complex and massive streaming analysis topologies with SAMOA building blocks. As a initial steps we have build a SAMOA streaming clustering topology as shown in the above figure to analyses stream data on-line. More details of the implementation can be found in Implementation.
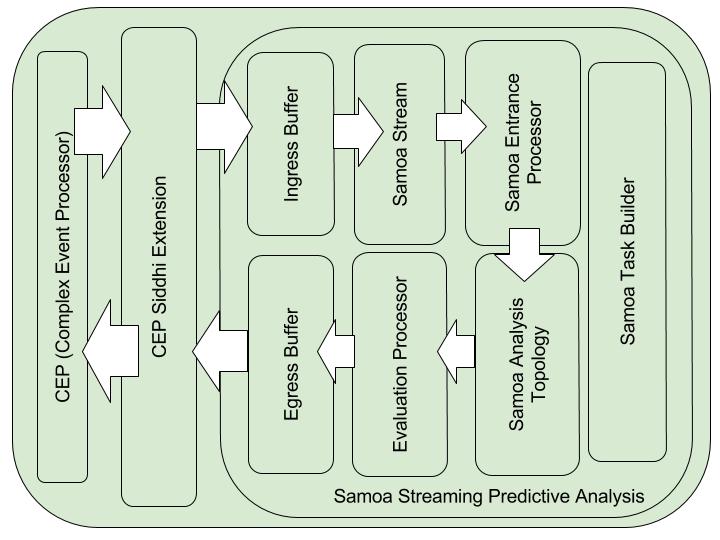
Both implementations anre JAVA based implementations. Samoa is using instances and InstanceStreams not Events and EventStreams like in CEP. Therefore stream data is buffered and convert from CEP events to SAMOA instances for analysis. CEP has their native ExecutionPlans to invoke predictive analysis which is used to build the predictive analysis Task in SAMOA core. Because of this preserving streaming analysis architecture for data streams as it is, model is retrained at every instance.
Flexibility and Adjust ability
We have parameterized both implementations and three scenarios where user can easily specify the type and nature of big data analysis that need. If we take analysis wise we have two: Streaming Linear Regression and Streaming Clustering analysis. We have three scenarios if we look at implementation wise. Both Streaming Linear regression and Steaming Clustering with Spark and Streaming Clustering with SAMOA. If we take analysis wide user can adjust following parameters.
- Learn Type: Learning method (batch-window, moving-batch-window, time-window)
- Window-Shift: Apply only when the moving batch window is applied
- Mini-Batch - Size: How often the ML model get retrained or updated
- Number of iteration: Number of iteration runs on the SGD algorithms
- Step-Size: related to Step Size of the SGD optimization algorithm.
- Mini-Batch Fraction: Fraction of the mini-Batch to process at every iteration in SGD algorithm.
- Confidence Interval : This is for future use if there will be any requirement
- Variable-List : feature Vector of the Data point
For the Streaming Clustering Analysis user can adjust following parameters according to the nature of the analysis.
- Learn Type: Learning method (batch-window, moving-batch-window, time-window)
- Window-Shift: Apply only when the moving batch window is applied
- Mini-Batch - Size: How often the ML model get retrained or updated
- Number of iteration: Number of iteration runs on the SGD algorithms
- Number of Clusters: Number of Clusters need for us
- Alpha : Decay Factor which can be used for Data obsolescence
- Confidence Interval : This is for future use if there will be any requirement
- Variable-List : feature Vector of the Data
Implementation
Implementation consist of three main components and three main CEP siddhi StreamProcessor Extensions. You can find the final code base of streamingml here. It is the final trimmed package.
- StreamingLinearRegression - Streaming Linear Regression with SGD based on Spark
- StreamingKMeansClustering - Streaming KMeans Clustering based on Spark
- StreamingClustring - Streaming Clustering based on SAMOA
Dependencies
As long as i use Maven to build with dependencies i use these following dependencies in my pom.xml . WSO2 CEP Siddhi Dependencies
<dependency>
<groupId>org.wso2.siddhi</groupId>
<artifactId>siddhi-core</artifactId>
<version> 3.0.6-SNAPSHOT </version>
</dependency>
<dependency>
<groupId>org.wso2.siddhi</groupId>
<artifactId>siddhi-query-api</artifactId>
<version> 3.0.6-SNAPSHOT </version>
</dependency>
Apache Spark Dependencies
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.6.1</version>
</dependency>
Apache SAMOA dependencies
<dependency>
<groupId>org.apache.samoa</groupId>
<artifactId>samoa-api</artifactId>
<version>0.4.0-incubating-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.samoa</groupId>
<artifactId>samoa-local</artifactId>
<version>0.4.0-incubating-SNAPSHOT</version>
</dependency>
Samoa dependencies are important. Since latest version of samoa 0.4.0-incubator is not in the maven repository you have two options. Either find remote repository or build samoa latest locally. In my case i use locally built Samoa 0.4.0-incubator. For more information of getting started with SAMOA click here . May be this link will be helpful too. And also please use the below dependency since it is using in SAMOA.
<dependency>
<groupId>com.github.javacliparser</groupId>
<artifactId>javacliparser</artifactId>
<version>0.5.0</version>
</dependency>
WSO2 CEP Siddhi Extension
All three components have their native CEP siddhi extensions based on the StreamProcessor Extension. CEP Extension is a one way of using the core components with outside data streams.These are the three classes extending CEP StreamProcessor.
public class StreamingLinearRegressionStreamProcessor extends StreamProcessor
public class StreamingKMeansClusteringStreamProcessor extends StreamProcessor
public class StreamingClusteringWithSamoaStreamProcessor extends StreamProcessor
And also to publish these extensions on the CEP server we have to follow two steps. We have to add following lines to .siddhiext file in the resources.
streamlinreg=org.wso2.carbon.ml.siddhi.extension.streamingml.StreamingLinearRegressionStreamProcessor
streamclustering=org.wso2.carbon.ml.siddhi.extension.streamingml.StreamingKMeansClusteringStreamProcessor
streamclusteringsamoa=org.wso2.carbon.ml.siddhi.extension.streamingml.StreamingClusteringWithSamoaStreamProcessor
Streaming Linear Regression with SGD based on Spark
Streaming Linear Regression classes are developed in the following way. If anyone want to use it without CEP siddhi extension, you have to intantiate the StreamingLinearRegression Class with correct parameters. Then call regress() function in the class with data points as double[].
public StreamingLinearRegression(int learnType,int windowShift,int paramCount, int batchSize, double ci, int numIteration, double stepSize, double miniBatchFraction)
then call the regression function regress() to train and retrain the ML models.
public Object[] regress(Double[] eventData)
Streaming KMeans Clustering based on Spark
Streaming KMeans Clustering can be used either as a CEP extension or standalone API. you just need to instantiate the StreamingKMeansClustering class with relevant parameters.
StreamingKMeansClustering(int learnType, int windowShift, int numAttributes, int batchSize, double ci, int numClusters, int numIterations, double alpha)
and also you just need to call the cluster() function with data point or event as double[] to train ML model.
public Object[] cluster(Double[] eventData)
Streaming Clustering based on SAMOA
Even though the internal structure and functionality is different than the Spark based streaming clustering solution you can use same call and instantiation for the StreamingClustering with Samoa based implementation.
public StreamingClustering(int learnType,int paramCount, int batchSize, double ci, int numClusters,int numIteration, double alpha){
to train the model with data/event with the correct instantiation you have to call cluster() function
public Object[] cluster(double[] eventData)
SAMOA Topology For CEP Integration
This is the challenging part of this entire project. Understanding SAMOA architecture and integrating it with the CEP event streams through CEP siddhi extension consumed time, but finally paid of with good results. As we discussed above StreamingClustering.java is the core module that integrate CEP extension with my SAMOA ML analysis topology.you can find necessary classes i developed for this at org.wso2.carbon.ml.siddhi.extension.streamingml.samoa . There you can see essential components for this integration for Streaming Clustering solution for CEP. In the same way you can develop your own classes to provide other streaming ml analysis on top of this essentials.These samoa supported classes are implemented in the org.wso2.carbon.ml.siddhi.extension.streamingml.samoa
- Streaming Clustering (StreamingClustering.java)
- Streaming Clustering Task Builder (StreamingClusteringTaskBuilder.java)
- Streaming Clustering Task (StreamingClusteringTask.java)
- Streaming Clustering Stream (StreamingClusteringStream.java)
- Streaming Clustering Entrance Processor (StreamingClusteringEntranceProcessor.java)
- Streaming Clustering Evaluation Processor (StreamingClusteringEvaluationProcessor.java )
Inside Streaming Clustering class there are ingress and egress buffers to buffer the streams and convert them from CEP side to SAMOA side and vise versa. Ingress queue for events or event data while egress queue consist of clustering model results such as number of clusters and cluster centers. This is inside StreamingClustering.java
public ConcurrentLinkedQueue<double[]>cepEvents;
public ConcurrentLinkedQueue<Clustering>samoaClusters ;
Streaming Clustering Task Builder is the one who invoke the my topology for learning and training. In that task builder it initialize the Task class which contains the information of the topology.When a new task is assigned the Task Builder builds the task with necessary parameters.
task.setFactory(new SimpleComponentFactory());
task.init();
SimpleEngine.submitTopology(task.getTopology());
When the task is identified as Streaming Clustering Task, it will be instantiated and initialize the ml topology successfully. When we take Streaming Clustering Task which inherited by samoa Task can be easily deployed as regular SAMOA Task at org.apache.samoa.tasks.Task.
public class StreamingClusteringTask implements Task, Configurable
Main idea of Task is to connect streams with processors and build a complex topology. In this clustering analysis case i connected my Streaming Clustering Stream with my Streaming Clustering Entrance Processor. And Then My entrance processor is connected to SAMOA Learning components sequential way or distributed way. Then the topology output is extracted by my Streaming Clustering Evaluation processor which send output model to egress buffer. When we take StreamingClusteringStream.java it is inherited from Samoa ClusteringStream. Or else we can inherit from samoa InstanceStream. Either way we have to generate InstanceStream which is very similar to CEP Event Streams. Because insode SAMOA every data point is processed as Instance.
public class StreamingClusteringStream extends ClusteringStream
In that StreamingClusteringStream.java we have to override some methods to feed custom streams into Samoa core for predictive analysis. If you want to define your own InstanceStream or custom stream that need to connect to Samoa you can simply override following methods as i did with following inside StreamingClusteringStream.java.
protected void prepareForUseImpl(TaskMonitor taskMonitor, ObjectRepository objectRepository)
public InstancesHeader getHeader()
public boolean hasMoreInstances()
public Example<Instance> nextInstance()
And SAMOA is using ContentEvent to pass through streams which contains elements what we need to process such as Instance. And to feed my streams into samoa toy have to override the my Entrance Processor: StreamingClusteringEntranceProcessor.java .
public ContentEvent nextEvent()
Finally we need to build evaluation or result capturing module from learners. Therefore i developed my StreamingClusteringEvaluationProcessor.java module to extract clustering results from Learning modules. In flexible samoa architecture we can define our own Learner modules to train ML models.
public class StreamingClusteringEvaluationProcessor implements Processor
Inside evaluation processor i have to override its process() method for this integration and get back results.
public boolean process(ContentEvent event)
Therefore now complete predictive analysis topology with SAMOA has already built. So now you can build and initialize the task.
Getting Started
If you are supposed to use WSO2 CEP framework to test the streamingml package download it. For more information please refer this. If you want to use this as a third party API you dont need WSO2 CEP.follow below steps streamingml package in your project.
git clone https://github.com/dananjayamahesh/streamingml.git
cd streamingml
mvn package
If you want to use it with CEP please follow the following steps and execute the siddhi queries listed in the next section. Please follow the instruction of WSO2 CEP documentation to create example execution plan. *Copy target/streamingml-1.0-SNAPSHOT.jar into CEP_HOME/repository/component/lib
- go to CEP_HOME/bin
- start the CEP by ./wso2server.sh
- Then create InputStream and OutputStream correctly. More info click here.
- Then go to Execution Plan and copy paste siddhi queries in the next section.
And in advance if you want to pack with the relevant jars for this streamingml package with it, please use the maven shade plugin that is commented in the pom.xml file. currently it is using the compiler plugin. Sometimes when CEP cannot identifies the necessary jars such as samoa it will give exceptions. So in that case you have to pack necessary jars inside streamingml jar file.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
Therefore if you want to pack necessary jars inside streamingml jar before you put it into CEP_HOME/repository/component/lib , uncomment maven-shade-plugin and comment the maven-compiler-plugin.When you do these steps now you can see two jars inside target/ folder. put both of them inside CEP_HOME/repository/component/lib folder and start CEP again.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>
reference.conf
</resource>
</transformer>
</transformers>
<instructions>
<Import-Package>
org.apache.spark.network.*;version="1.6.1";
</Import-Package>
</instructions>
<descriptorRefs>
<descriptorRef>
jar-with-dependencies
</descriptorRef>
</descriptorRefs>
<source>1.8</source>
<target>1.8</target>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
WSO2 Siddhi Queries for Streaming Analysis
Siddhi queries are one way of invoking Streaming ML modules in streamingml package.For this example i have been using CCPP dataset from UCI repository. Change streams and parameters to match your case. There are two types of invoking queries. One for Streaming Linear Regression and other one is Streaming Clustering. They are same and inorder as we discussed in the flexibility and adaptability section. But for your convenience i am interpret those query structure.
Streaming Linear Regression Query Structure
streamingml:streamlinreg( [learn-type], [window-shift], [mini-batch-size],[number-of-iteration], [step-size], [mini-batch-fraction], [ci], [Variable List])
Streaming Clustering Query Structure
streamingml:streamclustering( [learn-type], [window-shift], [batch-size], [number-iterations], [number-clusters], [alpha], [confidence-interval], [Variable List])
If you take Spark base one batch-size can be interpreted as the number of data events that the model will be trained and updated. But if you take the same batch-size parameter in SAMOA you can see that batch-size related to the number data events that the model will be updated to cep side, because at each instance or data point it retrain the model.
Siddhi Query for Streaming Linear regression (Spark Based)
@Import('ccppInputStream:1.0.0')
define stream ccppInputStream (PE double, ATV double, V double, AP double, RH double);
@Export('ccppOutputStream:1.0.0')
define stream ccppOutputStream (stderr double);
from ccppInputStream#streamingml:streamlinreg(0, 0, 1000,10, 0.00000001, 1.0, 0.95, PE, ATV, V, AP, RH)
select stderr
insert into ccppOutputStream;
If you want to get model parameters change the output stream according to extract them. OutputStream consist of model parameters.So you can use siddhi query like below where beta0 is the intercept of the streaming regression model.
@Import('ccppInputStream:1.0.0')
define stream ccppInputStream (PE double, ATV double, V double, AP double, RH double);
@Export('ccppOutputStream:1.0.0')
define stream ccppOutputStream (PE double, ATV double, V double, AP double, RH double, stderr double, beta0 double, beta1 double, beta2 double, beta3 double, beta4 double);
from ccppInputStream#streamingml:streamlinreg(0, 0, 1000,10, 0.00000001, 1.0, 0.95, PE, ATV, V, AP, RH)
select *
insert into ccppOutputStream;
Siddhi Query for Streaming KMeans Clustering (Spark Based)
@Import('ccppInputStream:1.0.0')
define stream ccppInputStream (PE double, ATV double, V double, AP double, RH double);
@Export('ccppOutputStream:1.0.0')
define stream ccppOutputStream (PE double, ATV double, V double, AP double, RH double, stderr double, center0 string, center1 string);
from ccppInputStream#streamingml:streamclustering(0, 0, 1000, 10, 2, 1, 0.95, PE, ATV, V, AP, RH)
select *
insert into ccppOutputStream;
Siddhi Query for Streaming Clustering (SAMOA Based)
@Import('ccppInputStream:1.0.0')
define stream ccppInputStream (PE double, ATV double, V double, AP double, RH double);
@Export('ccppOutputStream:1.0.0')
define stream ccppOutputStream (PE double, ATV double, V double, AP double, RH double, stderr double, center0 string, center1 string);
from ccppInputStream#streamingml:streamclusteringsamoa(0, 0, 1000, 10, 2, 1, 0.95, PE, ATV, V, AP, RH)
select *
insert into ccppOutputStream
Likewise you can make use of siddhi query to change the analysis and parameter. Lets say you need 3 clusters and you want to get 3 cluster centers back, then you have to use like below,
@Import('ccppInputStream:1.0.0')
define stream ccppInputStream (PE double, ATV double, V double, AP double, RH double);
@Export('ccppOutputStream:1.0.0')
define stream ccppOutputStream (PE double, ATV double, V double, AP double, RH double, stderr double, center0 string, center1 string, center2 string);
from ccppInputStream#streamingml:streamclusteringsamoa(0, 0, 1000, 10, 3, 1, 0.95, PE, ATV, V, AP, RH)
select *
insert into ccppOutputStream
You can change batch-size and see how the model will be updated with the data streams. And one notification if you will use the carbon-ml extension in the future, then you have to use ml rather than streamingml in the siddhi query. As a example query can be found below.
from ccppInputStream#ml:streamclusteringsamoa(0, 0, 1000, 10, 3, 1, 0.95, PE, ATV, V, AP, RH)
select *
insert into ccppOutputStream
GSOC Final Evaluation Links
GSOC My Continuous Work here https://github.com/dananjayamahesh/GSOC2016).you can find samoa extensions and spark siddhi extension inside
gsoc/folder inside GSOC2016 repo. GSOC2016 repo contains all the major commits i have done during the GSOC periodstreamingml github repository here (https://github.com/dananjayamahesh/streamingml). This is the final essential part followed by GSOC2016 repository
streamingml integration with carbon-ml master branch here (https://github.com/dananjayamahesh/carbon-ml/tree/master/components/extensions/org.wso2.carbon.ml.siddhi.extension/src/main/java/org/wso2/carbon/ml/siddhi/extension)
carbon-ml PR here (https://github.com/wso2/carbon-ml/pull/232)
-
Documentation here
Author
Mahesh Dananjaya (@dananjayamahesh) (dananjayamahesh@gmail.com)